有些 NP-hard problem 在 input data 以 unaray 的形式表达时,可以使用 dynamic programming 在以 input size 为自变量的 polynomial time 解决,此时的 algorithm 被称为是 pseudopolynomial1 的。通过 rounding input value 可以得到一个 polynomial in the input size 的 approximation algorithm.
对于其他 problem, 则通常将 input instance 分为 “large” 和 “small” 两个部分,对 large input 进行 rounding, 然后使用 DP 在 polynomial-time 单独求解得到一个存在 error parameter 的 solution, 再通过一些方式结合 small input 得到最终的 solution.
The knapsack problem
给定 item 的集合 I={1,…,n}, 每个 item 有 value vi 与 size si, 所有 value 与 size 都是正整数。knapsack 的容量为 B, 也是一个正整数。要求出 item 的子集 S⊆I, 满足 ∑i∈Ssi≤B, 使得 ∑i∈Svi 最大。
经典的 DP 算法如下:

Algorithm 3.1 correctly computes the optimal value of the knapsack problem.
Algorithm 3.1 的时间复杂度为 O(nmin(B,V)), 其中 V=∑i∈Ivi. 若所有 input 都用 binary 编码,此时 input B 的 size 为 log2B, O(nB)=O(n2log2B) 为 input number B 的 exponential, 因此并不是 polynomial in input size.
An algorithm for a problem Π is said to be pseudopolynomial if its running time is polynomial in the size of of the input when the numneric part of the input is encoded in unary.
若 V 是 n 的 polynomial, 那么 O(nmin(B,V)) 就会是 n 的 polynomial. 我们可以通过将 vi round 到 n 的 polynomial 来得到一个真正的 polynomial-time (但是 approximation) algorithm, 合适的 rounding 技巧可以使结果的误差较小。
A polynomial-time approximation scheme (PTAS) is a family of algorithms {Aϵ}, where there is an algorithm for each ϵ>0, such that Aϵ is a (1+ϵ)-approximation algorithm (for minimization problems) or a (1−ϵ)-approximation algorithm (for maximization problems).
Aϵ 的 running time 会取决于 1/ϵ, 一般考虑在 1/ϵ 上有较好的 bound 的 algorithm:
A fully polynomial-time approximation scheme (FPAS, FPTAS) is an approximation scheme such that the running time of Aϵ is bounded by a polynomial in 1/ϵ.
下面给出一个 knapsack problem 的 FPAS. 考虑用一个与 n 有关 (polynomial in n) 的数 μ 来估计 vi, 将 vi round 到 vi′=⌊vi/μ⌋, 然后跑 Algorithm 3.1 得到 item 集合 S′, 最终算法得到的解即为 ∑i∈S′vi.
记最优解得到的 item 集合为 S, 则 μ∑i∈Svi′≥OPT−nμ, 由于 S′ 为此时的最优解,因此有 μ∑i∈S′vi′≥μ∑i∈Svi′≥OPT−nμ, 又 μ⋅∑i∈S′vi′≤∑i∈S′vi, 因此得到的解与 OPT 的差不超过 nμ. 由于算法(需要)是 (1−ϵ)-approximation, 因此解与 OPT 的差不应超过 ϵOPT. 记 M=maxi∈Ivi, 则显然有 OPT≥M, 不妨令 nμ=ϵM 控制误差恒不超过 ϵM, 得到 μ=ϵM/n, 于是 vi′=⌊ϵM/nvi⌋.

此时有 V′=∑i=1nvi′=∑i=1n⌊ϵM/nvi⌋=O(n2/ϵ), 算法的时间复杂度为 O(nmin(B,V′))=O(n3/ϵ), 满足 bounded by a polynomial in 1/ϵ.
Algorithm 3.2 is a fully polynomial-time approximation scheme for the knapsack problem.
Proof. 只需证明算法是 (1−ϵ)-approximation 即可。通过下列不等式可以证明:
i∈S′∑vi≥μi∈S′∑vi′≥μi∈S∑vi′≥i∈S∑vi−nμ=OPT−ϵM≥OPT−ϵOPT=(1−ϵ)OPT
Scheduling jobs on identical parallel machines
不难想到将 job 分为 short job 和 long job, 然后对数量被限制到常数级别的 long job 求出 optimal schedule, 再将 short job 按照 list scheduling 加入当前 schedule 中。
具体来说,将 pi≥km1∑i=1npi2 的 job 视为 long job, 则 long job 至多有 km 个,其中 k 为常数,若假定 m 也是常数,那么 long job 的数量也是常数级别,此时可以直接暴力求出 optimal schedule for long jobs, 总的状态数为 O(mkm) 为常数,然后对 short jobs 从大到小排序后按照 list scheduling 加入 schedule 得到最终的 schedule, 最后的时间复杂度为 O(nlogn+mkm)=O(nlogn), 瓶颈在于排序,显然属于 polynomial-time algorithm. 记此类算法为 {Ak}.
在上一章中 list scheduling 算法有结论
Cmax≤pℓ+j=ℓ∑pj/m,
其中 ℓ 为最晚完成的 job. 对于 Ak 得到的 schedule, 若最晚完成的 job 是 long job, 那么此时的 Cmax=Cmax∗; 若最晚完成的 job 是 short job, 根据结论有
Cmax≤pℓ+j=ℓ∑pj/m≤k1i=1∑npi/m+j=ℓ∑pj/m≤(1+k1)i=1∑npi/m≤(1+k1)Cmax∗
令 ϵ=k1, 则 Ak 是 (1+ϵ)-approximation polynomial-time algorithm.
The family of algorithms {Ak} is a polynomial-time approximation scheme for the problem of minimizing the makespan on any constant number of identical parallel machines.
如果只在最晚完成的 job 是 long job 时才对 long job 计算 optimal schedule, 否则沿用 knapsack 的 DP 方法计算一个非最优的 schedule, 这样可以移除 m 是常数的限制。
由于 Cmax∗ 未知,不妨设 target length 为 T, 令 pj≥T/k 的 job 为 long job, 若设置的 T≥Cmax∗, 此时 long job 的数量相对少,可以利用 DP 在 poly-time 得到一个关于 T 的近似解,然后便可调小 T 值;若设置的 T<Cmax∗, 此时 long job 的数量较多,poly-time 内难以找到与 T 相关的近似解,因此可以 return false 并调大 T 值,最终会得到一个 ≤Cmax∗ 的 T 值并由此计算出一个近似解,最后再利用 list scheduling 加入 short job 即可。
记上述算法为 {Bk}, 具体过程如下:将 long job 的 length round 到最近的 T/k2 的倍数 i⋅T/k2, 之后只需要关心 i 而不是 pj. 在 target length 为 T 的设定下,每个 machine 会被分配的 job 至多 T/kT=k 个,并且最大的 job 满足 pj≤T (否则必然有 T<Cmax∗), 因此按照 i 分类的话 long job 至多可以分为 T/k2T=k2 类,于是每个 machine 的状态可以用一个 k2 维的 vector (s1,s2,…,sk2) 表示,当满足下列不等式时称它为 machine configuration:
i=1∑k2si⋅iT/k2≤T.
记所有 machine conofiguration 构成的集合为 C, 则 ∣C∣≤(k+1)k2, 为常数级别。
然后 DP (类似分组背包) 的状态方程为
OPT(n1,…,nk2)=1+(s1,…,sk2)∈CminOPT(n1−s1,…,nk2−sk2).
可以在 O(m⋅∣C∣) 时间内求出 round 后的最优解。由于限定了单个 machine 的 load ≤T, 设该解在任意 machine 上分配的 job 集合为 S, 有 ∣S∣≤k, 且单个 job 满足 pj−pj′≤T/k2, 所以有
j∈S∑pj≤T+k⋅T/k2=(1+k1)T.
于是 DP 的近似解满足 Cmax′≤(1+k1)T, 且如果 T<Cmax∗ 就无法找到合法的解,最后加上 short job 不难证明在最后完成的 job 是 short job 时,由于 ∑j=1npj/m≤T, 于是
Cmax≤pℓ+j=ℓ∑pj/m≤T/k+T=(1+k1)T.
因此,{Bk} 会在 poly-time 内要么返回 T 无解要么返回 Cmax≤(1+k1)T 的解。
设
L0=max{⌈j=1∑npj/m⌉,j=1,…,nmaxpj},R0=⌈j=1∑npj/m⌉+j=1,…,nmaxpj,
作为 T 的上下界然后二分即可,最后得到的 T≤Cmax∗, 因此 {Bk} 可以给出 Cmax≤(1+k1)Cmax∗ 的解,再令 ϵ=k1, 于是 {Bk} 为 (1+ϵ)-approximation poly-time algorithm.
There is a polynomial-time approximation scheme for the problem of minimizing the makespan on an input number of identical parallel machines.
由于 DP 的状态数为 O((k+1)k2), 即 exponential in O(1/ϵ2), 因此 {Bk} 并不是 FPAS.
事实上,这个 scheduling problem 是 strongly NP-complete 的:即使将每个 job 的 processing time 限制为 q(n), 在这个特殊情况下也依旧是 NP-complete 的。若存在解决该 scheduling problem 的 FPTAS, 那么就可以令 k=⌈2nq(n)⌉≥2nP, 其中 P=maxj=1,…,npj, 于是算法的解满足 Cmax≤(1+k1)Cmax∗≤Cmax∗+21, 由于 Cmax,Cmax∗ 为整数,因此 Cmax=Cmax∗, 从而存在算法在 poly-time 解决 processing time 被限制为 q(n) 的 scheduling problem, 从而可以推出 P=NP.
一个更 general 的结论是:对于任意优化问题,若该问题是 strongly NP-complete 的,那么它不存在 FPAS.
The bin-packing problem
bin-packing problem 指的是下列问题:
给定 n 个大小分别为 a1,a2,…,an 的 pieces (或 items), 满足
1>a1≥a2≥⋯≥an>0;
我们希望将这些 pieces 装进尽可能少的 bins, 其中每个 bin 的容量为 1.
bin-packing problem 的特殊情形下可以转化为 partition problem: 给定 n 个正整数 b1,…,bn 满足 B=∑i=1nbi 为偶数,问能否将下标集合 {1,…,n} 划分为集合 S 和 T 使得 ∑i∈Sbi=∑i∈Tbi.
只需令 ai=2bi/B 并检查能否装进 2 个 bin 即可将 bin-packing problem 转化为 partition problem. 由于 partition problem 是 NP-complete 的,于是有下列 theorem.
Unless P=NP, there cannot exist a ρ-approximation algorithm for the bin-packing problem for any ρ<3/2.
记 FFD(I) 为 First-Fit-Descreasing 算法运行在 instance I 时得到的需要的 bin 的数量,OPT(I) 表示 I 最少需要的 bin 数量,有证明表示,对于任意 instance I 都有 FFD(I)≤(11/9)OPT(I)+4.
事实上,如果允许存在 small additive terms, 我们可以找到算法使得它得到的 packing 不会使用超过 OPT(I)+1 个 bin.
尽管有 Theorem 3.8 的结论,bin-packing problem 在允许 small additive terms 时却可以做到优化乘法系数是因为它没有 rescaling property, 即对于任意 input I 和任意值 K, 可以构造一个等价的 instance I′ 使得 objective function value of any feasible solution is rescaled by K.
前面讨论的所有 weighted problem 都拥有 rescaling property, ρOPT+c 的 solution 都可以等价转化得到一个 ρ-approximation 算法,例如 Section 3.2 中的 scheduling problem 若将所有 pj 乘上系数 K 就能利用结果是整数的特性摆脱 additive terms. 因此只需考虑 no additive terms 的情形即可。
下面设计一系列 poly-time approx algorithms parameterized by ϵ>0, 其中每个算法都在任意 input I 下保证得到的 packing 所需 bin 数量不超过 (1+ϵ)OPT(I)+1. 这样的算法不满足 PTAS 的定义,这启发了下列定义。
An asymptotic polynomial-time approximation scheme (APTAS) is a family of algorithms Aϵ along with a constant c where there is an algorithm Aϵ for each ϵ>0 such that Aϵ returns a solution of value at most (1+ϵ)OPT+c for minimization problems.
bin-packing problem 与前面 scheduling problem 中关于 T 的 decision problem 部分十分相似,不难想到用相同的 DP 来解决 bin-packing problem. 这要求:
- 将 pj 除以 T 得到 input for bin-packing problem
- 不同的 piece size 数量需要是常数
- 利用 linear grouping scheme
- 每个 bin 能放入的 piece 数量是常数
具体而言,设定 threshold γ, 仅对 ai≥γ 的 piece 进行 DP, 令 SIZE(I)=∑i=1nai, 则需要 DP 的 piece 不超过 SIZE(I)/γ 个,lemma 3.10 表明加入 small pieces 后结果的上界:
Any packing of all pieces of size greater than γ into ℓ bins can be extended to a packing for the entire input with at most max{ℓ,1−γ1SIZE(I)+1} bins.
Lemma 3.10 的证明依赖于 First-Fit algorithm,记 First-Fit 算法的结果为 FF(I), 这里不妨先证明 FF(I)≤2OPT(I)+1. 假设已经使用了 ℓ 个 bin, 当前 piece 被放入第 ℓ+1 个 bin 当且仅当前 ℓ 个 bin 都放不下该 piece, 对于单个 bin 的情况不方便分析,但是两个 bin 结合起来就可以发现它们满足一些有用的 property:将 bin 1 和 bin 2 结合,bin 3 和 bin 4 结合,如此下去,当且仅当前 2k−1 个 bin 无法放入当前 piece 时会开启第 2k 个 bin, 因此这之后第 2k−1 个 bin 与第 2k 个 bin 所使用的容量之和必然 >1, 从而若一共使用了 ℓ 个 bin, 那么有 SIZE(I)≥⌊ℓ/2⌋, 于是 FF(I)≤2OPT(I)+1.
Proof of Lemma 3.10. 考虑 small pieces 按照 First-Fit 放入。若所有 small pieces 都被放入了原有的 ℓ bins 中,那么答案显然是 ℓ. 若当前的 small piece 被放入了一个新的 bin, 不妨设为第 k+1 个 bin, 那么前 k 个 bin 的剩余容量都 ≤1−γ, 这样的 bin 至多有 1−γ1SIZE(I) 个,于是答案至多为 1−γ1SIZE(I)+1, 得证。
若我们希望设计的算法的 performance guarantee 为 1+ϵ with 0<ϵ<1, 可以令 γ=ϵ/2, 于是 1/(1−ϵ/2)≤1+ϵ, 又有 SIZE(I)≤OPT(I), 从而最终的 composite algorithm 可以得到至多包含 max{ℓ,(1+ϵ)OPT(I)+1} 个 bin 的 packing.
然后将这部分需要 DP 的 piece 按照 size 从大到小每个 k 个分为一组, 最后一组的 piece 数量记为 h≤k 个,再按照 Section 3.2 中的方式进行 DP, linear grouping 后的最优解与 grouping 前的最优解的大小关系如下:
Let I′ be the input obtained from an input I by applying linear grouping with group size k. Then
OPT(I′)≤OPT(I)≤OPT(I′)+k,
and furthermore, any packing of I′ can be used to generate a packing of I with at most k additional bins.
Proof idea. 从下图看很显然
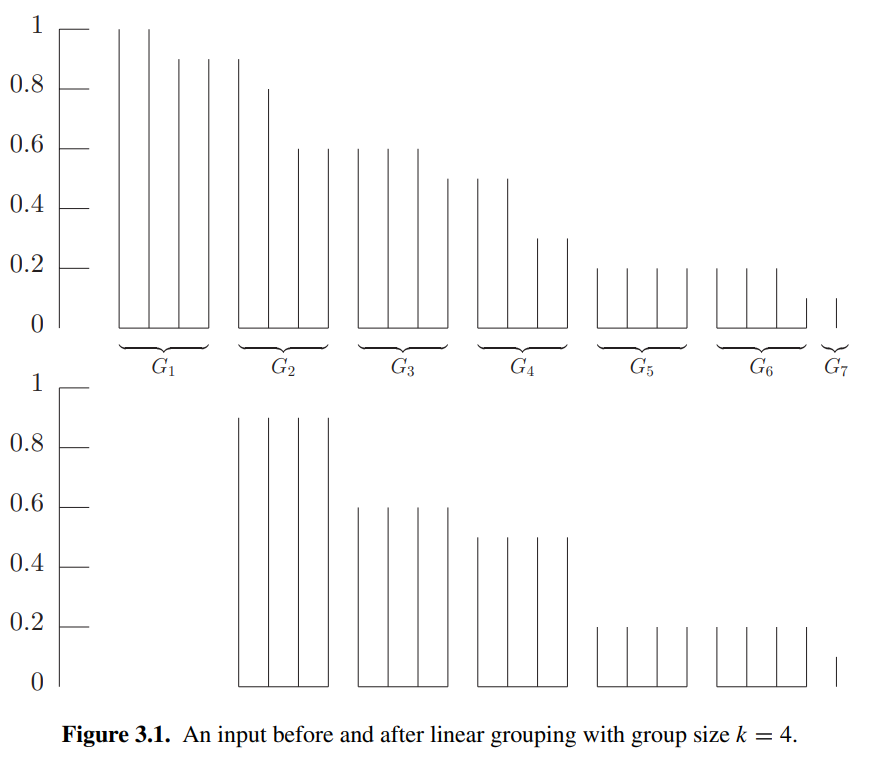
最后分析算法性能来设定 k. I′ 包含不同 size 的数量至多为 n/k, 其中 n 是 I 中 piece 的数量,而 I 中去除了 small pieces, 从而 SIZE(I)≥ϵn/2. 令 k=⌊ϵSIZE(I)⌋, 于是 n/k≤2n/(ϵSIZE(I))≤4/ϵ2, 当 ϵSIZE(I)<1 时 large pieces 足够少可以直接 DP, 因此这里假定了 ϵSIZE(I)≥1. 再结合 Lemma 3.10, 最终的 bin 数量不会超过 (1+ϵ)OPT(I)+1.
For any ϵ>0, there is a polynomial-time algorithm for the bin-packing problem that computes a solution with at most (1+ϵ)OPT(I)+1 bins; that is, there is an APTAS for the bin-packing problem.
Comments